
AI Security: Model Serialization Attacks
Navigating the Pitfalls of Model Serialization And ML Supply Chain Vulnerabilities: Best Practices for AI Security

The AI security landscape is fraught with novel attack vectors that exploit the unique vulnerabilities of machine learning systems: model poisoning and image scaling attacks, for example, represent a new wave of threats that are distinctly different from those found in the more traditional AppSec or Cloud security ecosystems.
Unlike the previous examples, this article focuses on a familiar attack vector: the execution of untrusted code. This long-standing issue has plagued application security for decades, and the AI field is no exception. In fact, the problem of dealing with untrusted code is just as relevant in AI as it is in other areas of cybersecurity.

A vulnerable Flask API that feeds unsanitized user input to the infamous Python `eval`:
One of the core principles in InfoSec is to never run untrusted code without first thoroughly validating and sanitizing its inputs, strictly limiting its execution environment through sandboxing or virtualization, and applying the principle of least privilege to minimize the blast radius in case of a compromise.
As we mentioned in our first article, the machine learning industry is at a less mature stage in terms of security culture than the cloud and application development ecosystems. This is partly because, until not too long ago, the AI field was partially decoupled from customer-facing commercial applications as a substantial portion of its practitioners were scholars.
Understanding Model Serialization Attacks
Model Serialization Attacks are one of the main security blind-spots in the ML industry. They are, essentially, a form of arbitrary code execution: the only novelty is that they target the MLOps lifecycle rather than Web API endpoints.
Serialization is the process of converting an object into a format that is more portable and that can be more easily stored and shared. Conversely, deserialization reconstructs the original artifact from its serialized format.
In the machine learning field, ML models are often serialized for storage and distribution and then deserialized before their production deployment. As complex and valuable digital artifacts, machine learning models move across the software supply chain and they are shared across many different systems, making them vulnerable to supply chain attacks.
Model Serialization Attacks are a form of supply chain attack.
When you deserialize an ML model, you are running untrusted code in your machine. Unsurprisingly, this is one of the main gateways that attackers use to hack the AI supply chain.
Platforms like Hugging Face - which enables users to share ML models and datasets- are especially exposed to this security risk: there have already been a few occurrences where MLSecOps researchers detected malicious models in public hubs.
Downloading one of these seemingly harmless ML models could potentially enable an attacker to spawn a shell in the victim’s machine.
More generally, compromising a machine learning model with remote code execution (RCE) can weaponize the AI supply chain into a distribution channel for malwares.
But what specific serialization weaknesses do RCE exploits leverage to compromise ML assets?
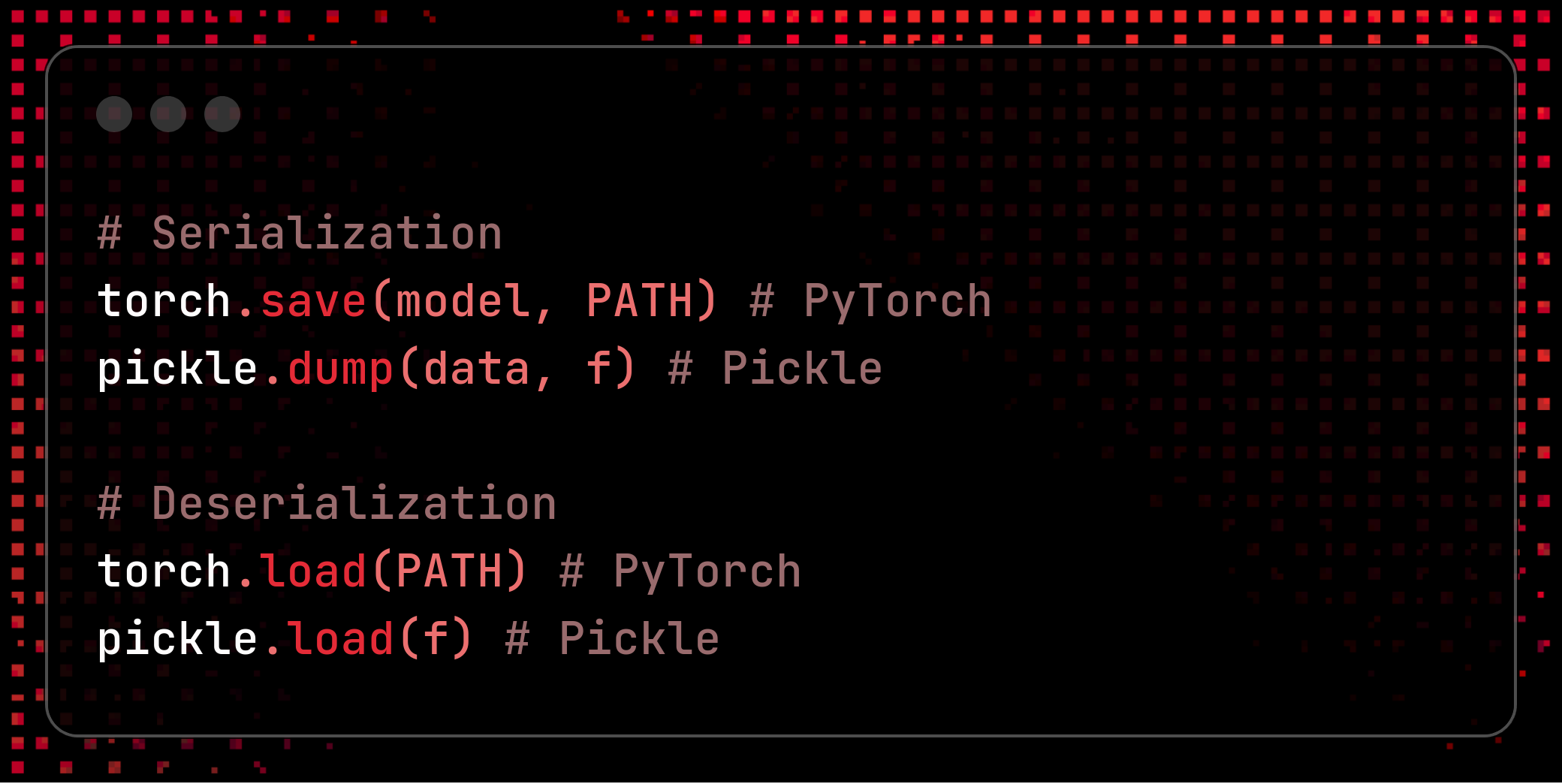
All the most popular ML development libraries - such as Tensorflow or PyTorch- come with built-in serialization utils, but only few are reasonably safe. The most widely used serialization library happens to be also the most unsafe: Pickle.

Pickle is THE Python serialization module in terms of popularity - image courtesy of DALL-E
In the Pickle library jargon, serialization and deserialization are referred to as, respectively, pickling and unpickling: when you pickle an object, you transform it into a byte stream with either .pkl or .pickle as file extensions - whereas unpickling reconstructs the binary file into its original format.
Some other ML serialization utils are built on top of Pickle, most notably PyTorch’ saving/loading model methods: PyTorch code has, in fact, already been found vulnerable of a few RCE exploits.
Exploiting Python Pickle
The main downside of Pickle is its lack of safety: it grants unrestricted execution to untrusted code, which makes it easily exploitable.

unsafe_pickle.py file in the damn-vulnerable-ML-serialization repository
In the above example, the attacker defines a MaliciousPayload class which, when deserialized, executes arbitrary shell commands on the victim's machine. The malicious instructions are embedded at the pickling stage, which are then triggered when pickle.dumps() deserializes the MaliciousPayload class instance.
A brief anatomy of the Pickle lifecycle
When the victim runs the unsafe_pickle.py file, the pickle.dump operation converts the MaliciousPayload instance into a byte-stream, which is then saved as the file damn_vuln_pickle_model.pkl. Furthermore, upon pickling, the `__reduce__()` method of the MaliciousPayload class is automatically invoked.
Let’s review the return signature of the `__reduce__()` method:

where:
`callable_object` is a Python callable: namely, an object that can be called like a function.
`tuple_args` is a tuple of arguments that will be passed to the `callable_object`
The reason why `__reduce__()` is such a security liability is because it serializes the callable_object and its arguments: - in our proof-of-concept, the callable_object is os_system and tuple_args is a crafted payload of bash commands.
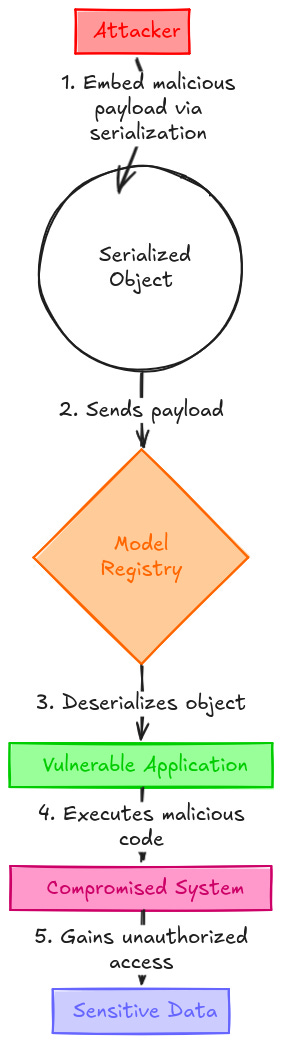
high-level walk-through of the serialization exploit
Finally, during unpickling, the callable and tuple are reconstructed into an executable and its arguments.
This means that when the code reaches the pickle.loads() instruction, the exploit runs the malicious shell commands.
In a real-world scenario, this type of exploit could be used to mount a backdoor on the victim’s machine, exfiltrate sensitive data or conduct a poisoning attack.
In the case of Pickle vulnerabilities, the exploit is embedded during the serialization stage - however, there are other variants of the exploit which target a different stages of a model’s lifecycle.
If you want to know more about MLSecOps, become a newsletter subscriber!
Mitigation Strategies
The three key action items for an effective prevention strategy against serialization attacks and enforce secure ML practices are:
Replacing Pickle with safer alternatives: Hugging Face, as one of the main targets of model serialization attacks, allocated its engineering resources to develop a much safer alternative to pickle called safetensors.
Set up a model registry to have greater visibility on the data provenance of your ML artifacts: supply chain security is even more critical in AI than it is in application development - and just as code repositories have tools like Backstage for better inventory management, the machine learning world has MLFlow.
Implement MLSecOps CI/CD in your model lifecycle: the two main security tools specialized in ML serialization attacks are ProtectAI’s ModelScan and Trail of Bits’ Fickling.
The companies that developed the aforementioned scanners are already established in the MLSecOps space in general and, in particular, they are not new to model serialization exploits: ProtectAI unconvered a few vulnerabilities in the MLFlow platform, whereas Trail of Bits (ToB) audited Hugging Face’s safetensors.
Both scanners are developer-friendly open-source Python packages that can be easily run from CLI, but they come with their own design trade-offs:
ModelScan is more of a blue team tool, which can be easily integrated with CI/CD in your MLOps lifecycle and helps your organization to identify dangerous serialization patterns. While it has less functionalities than Fickling, it supports more serialization utils and formats than the ToB’s scanner.
Fickling has a more red-team design, which includes a decompiler and the ability to perform code injection - as such, Fickling has a richer feature set than ModelScan, . On the downside, unlike the ProtectAI’s counterpart, ToB’s tool supports only Pickle or Pickle-based serialization utils - such as PyTorch.
Let’s now have a look at how we can run them against the vulnerable unsafe_pickle.py’s output:
ModelScan CLI command and output:


Fickling CLI command ’s safety-check flag and output:


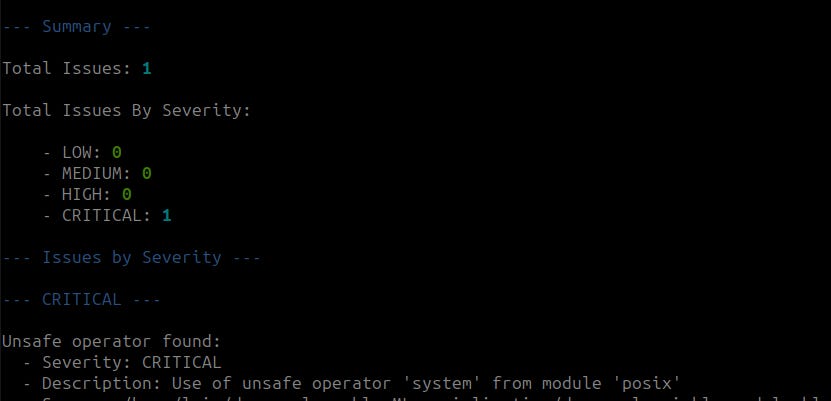


Bingo! Both scanners detected the security issue. If you want to check other vulnerable ML serialization examples with tensorflow and pytorch, then clone the damn-vulnerable-ML-serialization repository.
This is the end, my only friend
Time to wrap up our second MLSecOps article - in summary, understanding the risks associated with AI supply chain in general and model serialization in particular is critical to secure MLOps pipelines.
If you found this article informative, help us by sharing it on social media.
The next deep-dives in our content pipeline: from a HuggingFace safetensors walkthrough to the best practices to secure your LLM against prompt injection and an additional follow-up on ML serialization attacks and tools.
🔥 Passionate about AI security? Don't miss out our next articles and become a subscriber!
🔥 Looking for the the most comprehensive resource aggregator to explore the MLSecOps ecosystem?
👉 Check out the awesome-MLSecOps repository - the leading repository on AI Security featuring lists of AI security tools, academic papers and attack vectors, MLSecOps learning roadmaps and a rich bibliography of other industry-leading resources.
👀 Found the Awesome MLSecOps content helpful? Share some love by starring the repository on GitHub!
🔥 Looking for an introduction to MLSecOps? Check out our previous article What is MLSecOps?
🔥 Any Feedback?
👉 Connect with us on X (Twitter) for daily AI Security updates
👉 Join the conversation on Linkedin